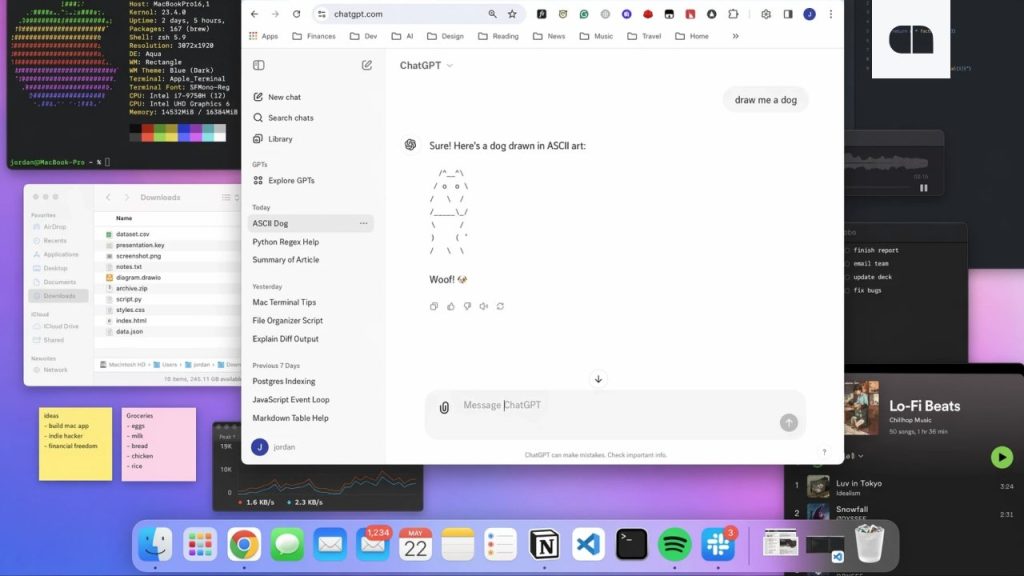
Ще кілька років тому моделі часто «вигадували» слова або робили помилки навіть у простих речах — наприклад, у меню ресторану. Тепер же нова версія здатна створювати зображення з текстом, який виглядає природно та без помилок.
Images 2.0 — перша модель генерації зображень у ChatGPT із так званими thinking-функціями. Вона може:
шукати актуальну інформацію в інтернеті;
створювати кілька варіантів зображень за одним запитом;
перевіряти власні результати.
Це дозволяє працювати зі складними задачами — наприклад, створювати серії коміксів, маркетингові кампанії чи навчальні матеріали.
Скриншот MacBook, повністю згенерований новою моделлю GPT Images 2.0 / OpenAI
Краще працює з мовами
Images 2.0 також значно покращила відтворення не латинських текстів — зокрема японської, корейської, гінді та бенгальської мов.
У компанії зазначають, що модель здатна точно передавати дрібні деталі: текст, іконки, елементи інтерфейсу та інші складні композиції.
Максимальна якість зображень — до 2K.
Зображення, згенероване новою моделлю GPT Images 2.0 / OpenAI
Попри покращення, генерація складних зображень займає більше часу, ніж звичайні текстові відповіді — іноді кілька хвилин.
Модель стане доступною для всіх користувачів ChatGPT і Codex, а платні користувачі отримають розширені можливості. Також OpenAI відкриє доступ до API (gpt-image-2) для розробників.
Водночас модель має обмеження за актуальністю знань — її дані охоплюють інформацію лише до грудня 2025 року, що може впливати на генерацію контенту, пов’язаного з новими подіями.